Database Indexing explained - Hussein Nasser
Database Indexing Explained (with PostgreSQL)
- We try and avoid reading from disk as much as possible.
- When reading from non-indexed columns, the only way to satisfy queries is to sequentially go through the fields.
# How do indexes make databases read faster? - Arpit Bhayani
How do indexes make databases read faster?
-
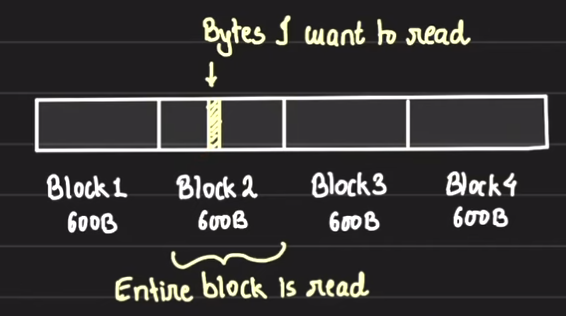
Any reads from disk will made in
blocks, -
These
blocksare sequential and represent the unit from which read operations are made.- Additionally, to read a specific portion of data, the entire block context needs to be read.
- If each record/row is
200Blarge, then a single block could then represent 3 records. - These records will be serialised sequentially on disk.
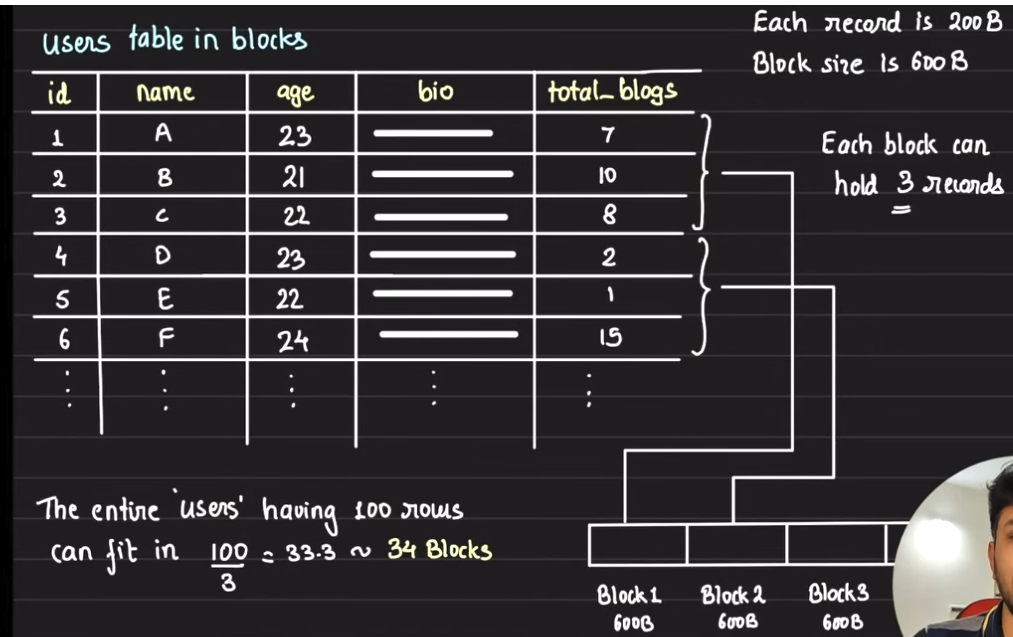
- Additionally, to read a specific portion of data, the entire block context needs to be read.
-
Index high level definition:
- Indexes are small referential tables that hold row references against the indexed value.
- Functionally, Indexes are virtually 2 column tables.
- Indexes are SORTED by the indexed value.

Example flow of index efficiency:
Query flow for non-indexed output:

Output flow if utilising index

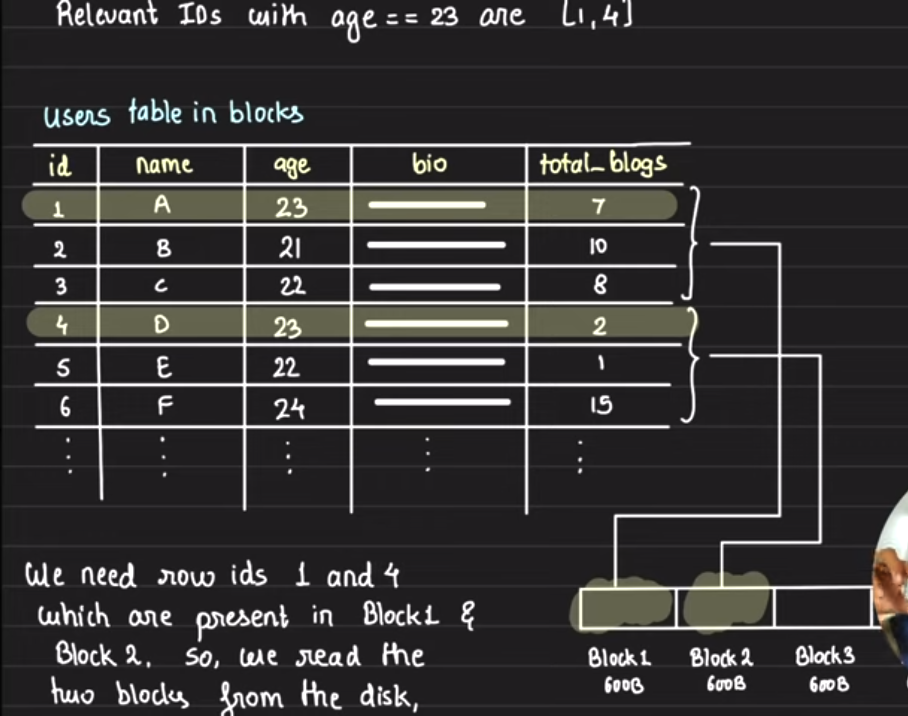
 A major feature to note is that indexes are ORDERED.
A major feature to note is that indexes are ORDERED.
- The natural order for records written to disk is instead in the natural order the data was written — unordered.
- This allows queries context to optimise WHERE within the index data structure to look, to find the desired records.
- It eliminates unnecessary iterations over tables.
This is why we want to make sure we are querying on columns that are indexed! This avoids needing to run sequential reads of entire tables (full table scans/
COLL_SCAN).